Overview
The main bottleneck in supervised learning of expressive policies in online RL is not expressivity itself, but where supervision comes from. Prior methods obtain supervised targets by reweighting samples from a global proposal (global IS), but in high-dimensional action spaces these samples rarely fall near target-relevant actions. The resulting proposal–target mismatch causes weight degeneracy and provides only sparse supervision for policy improvement.
FLAG addresses this bottleneck by localizing the target-matching problem (local IS). Compared to the global IS, FLAG conditions both distributions on the same flow latent variable , so importance sampling is performed inside a shared latent-conditioned local region. This gives the proposal meaningful overlap with the target where policy improvement actually occurs.
This simple shift from global IS to local IS makes supervised MaxEnt-RL practical for flow policies: no BPTT, few importance samples, and state-of-the-art performance.
Multi-goal Environment (Didactic Experiment)

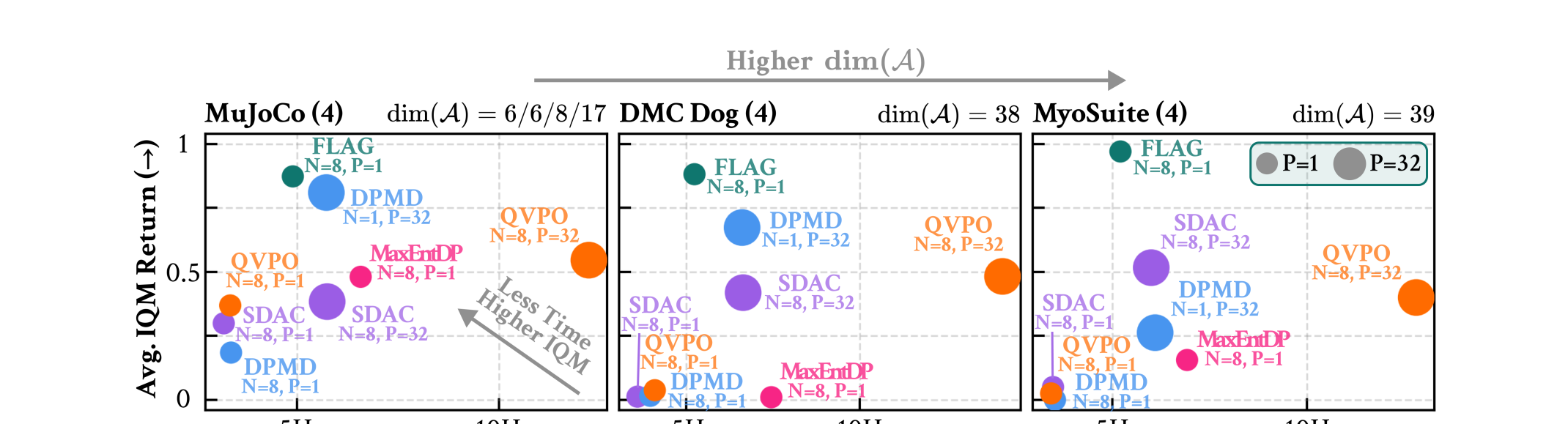
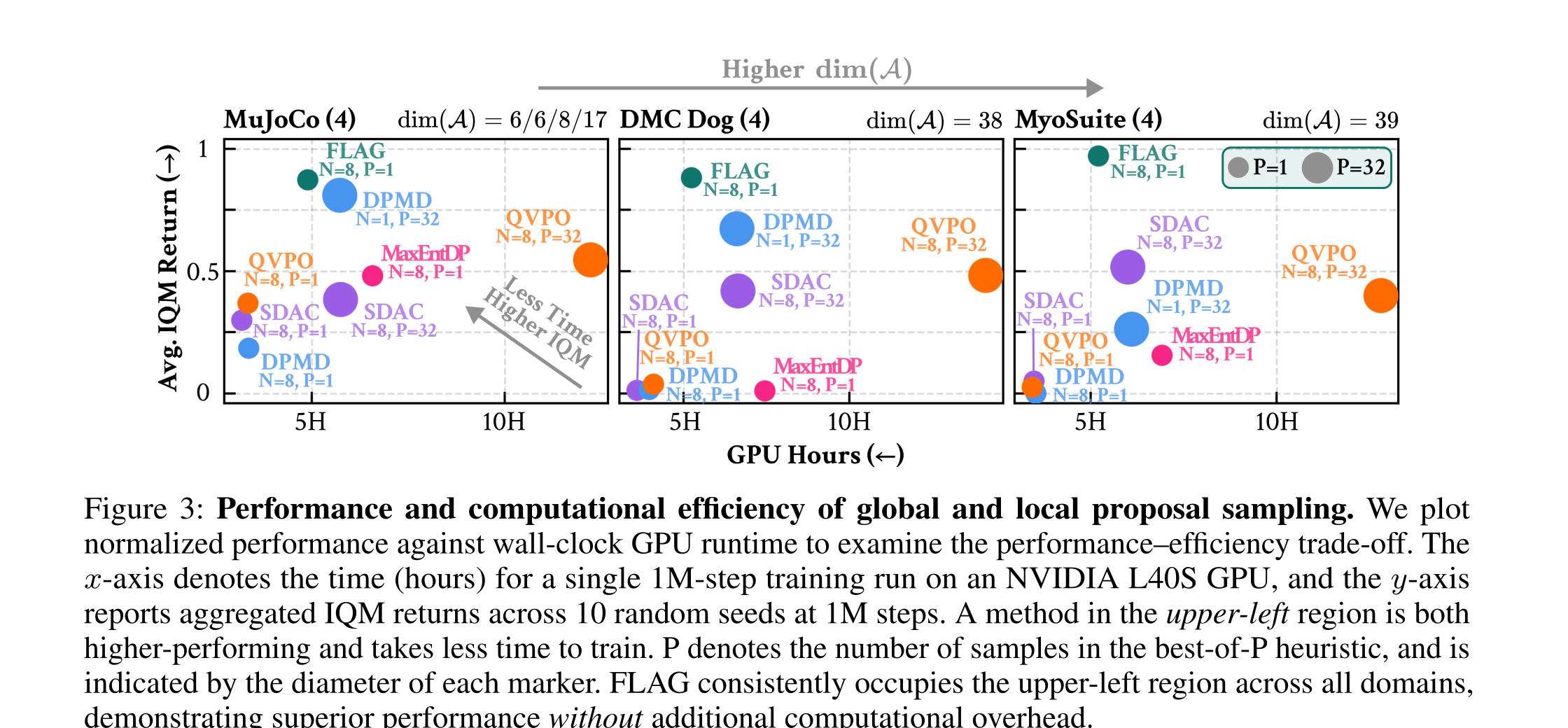
Main Result: Scaling to High-dimensional Control
FLAG sustains the highest return at low GPU cost as action dimensionality scales (MuJoCo → DMC Dog → MyoSuite). Detailed comparisons across budgets and critic settings are in Experimental Results · Q1.
Method
Expand each Q card to follow the argument. Q1–Q3 can be expanded; open a card to read its step-by-step reasoning.
Use the tabs: Challenge → Solution → Bottom Line. Each tab is one stage of the answer — start with the problem, then the construction, then the takeaway.
Q1 How do we construct local IS, and is it consistent with the original MDP?
For local IS to be principled — not just a trick — two conditions must hold:
- Localization. The proposal and target distributions must share a region indexed by a latent .
- Consistency. Optimizing inside that local region must be the same optimization problem as optimizing the RL objective in the original MDP.
Without Consistency, local IS optimizes the wrong objective and any gains are illusory.


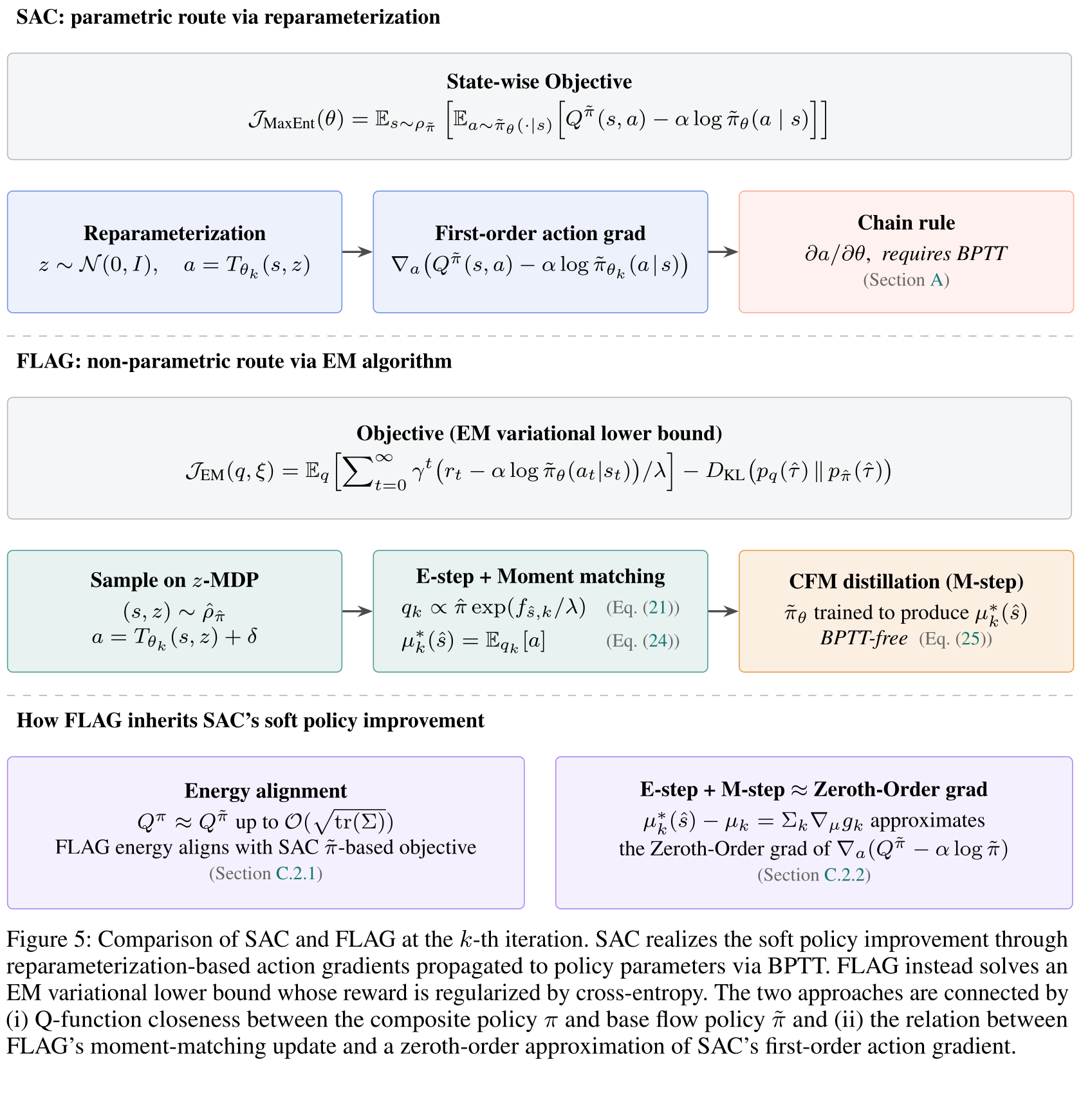
Q2 How do we incorporate this into MaxEnt-RL and update the policy?
Two obstacles block plugging the z-MDP into MaxEnt-RL:
- Intractable Entropy. The composite policy’s log-probability requires marginalizing over the latent — there is no closed form.
- RL via Supervised Learning. We want to cast MaxEnt-RL as an EM algorithm whose policy update reduces to a supervised learning problem — avoiding backprop through the flow ODE (BPTT).


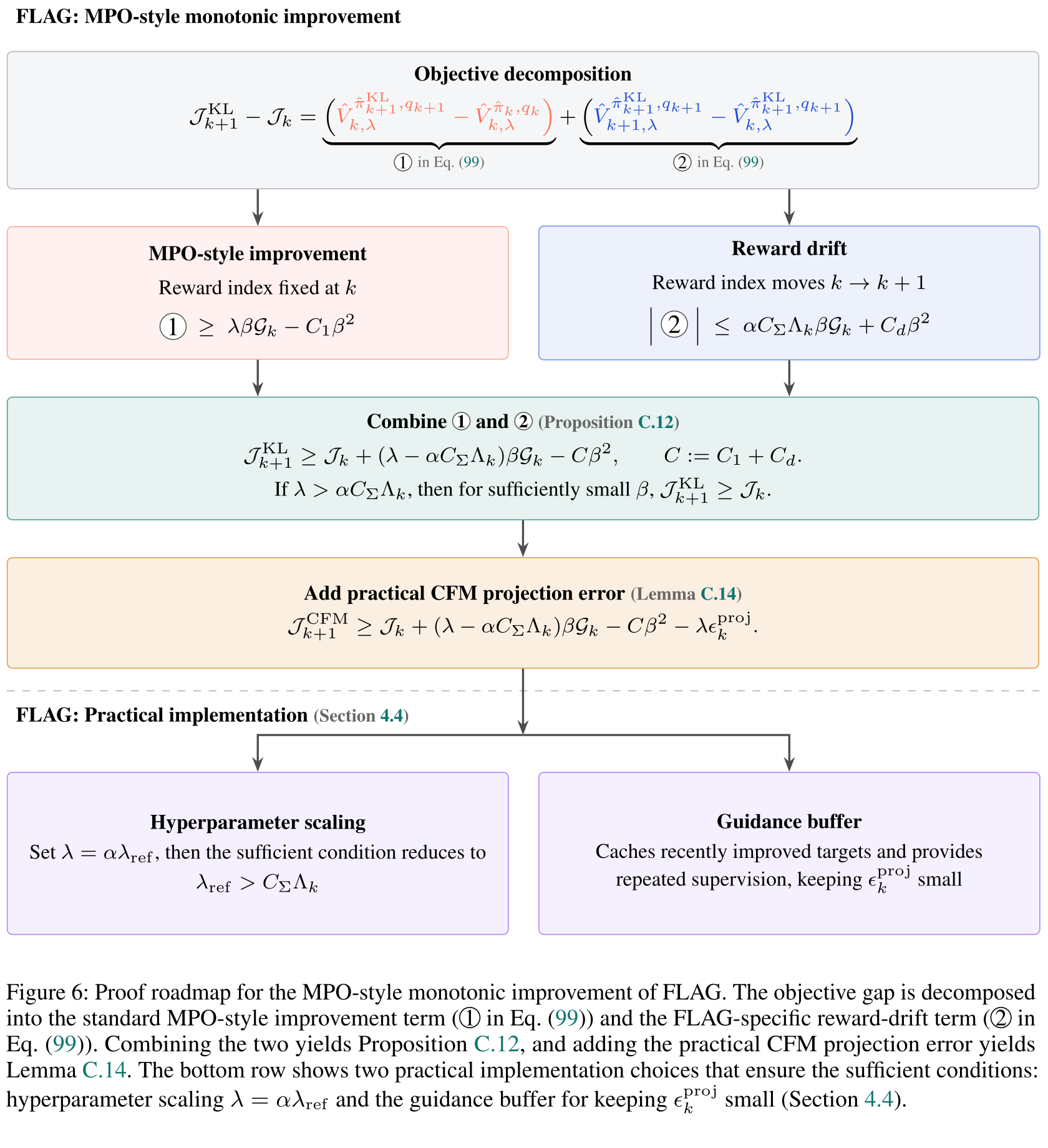
Q3 Does FLAG provably improve the policy, and how does it relate to SAC?
FLAG updates the policy by supervised distillation, not by differentiating the objective through the flow. Two guarantees are therefore not obvious — and this section establishes both:
- Monotonic improvement. Does FLAG’s update actually raise the objective, i.e. is guaranteed?
- Relation to SAC. We optimize a MaxEnt-RL objective — so how does FLAG’s update relate to Soft Actor–Critic (SAC), and does it inherit SAC’s soft policy improvement?
Experimental Results
We present the results around the three questions used in Section 5 of the paper.
Expand each banner to reveal results. Q1/Q2/Q3 cards and nested sub-banners (e.g., Q1.1) hide figures and tables until opened.
Click images to view detailed figure/table with caption. Cards show clean caption-free previews; the enlarged view shows the original caption from the paper.
best-of-P: when sampling actions from the policy (e.g., during rollout and policy update), P candidate actions are drawn and the one with the highest Q-value is selected.
Q1 Does FLAG scale to high-dimensional action spaces under limited sample budgets?
Q1.1Is FLAG scalable to high-dimensional action spaces?
FLAG stays in the high-return, low-runtime region as action dimensionality increases, while global-proposal baselines degrade or require larger best-of-P budgets.
Q1.2Is FLAG robust to the sample budget?
Local proposal matching keeps importance samples informative even when the update uses only a small number of samples.
Learning curveLearning Curves
Q2 How does FLAG compare to action-gradient and BPTT-based actor-critic methods?
Without CrossQ, critic gradients become less reliable.
FLAG remains effective because it aggregates critic signals into target actions rather than differentiating through the critic directly.
Q3 How do our key design choices---covariance scheduling and the guidance buffer---connect to the theoretical results?
A3.1Covariance SchedulingControls σ²ₖ · Theorem 4.5 (Q3) ↑
Annealing the local covariance suppresses the covariance-dependent reward drift in Theorem 4.5 while preserving enough early exploration.
| σinit (σfinal) | -1(-1) | -1(-2) | -1(-3) | -2(-2) | -2(-3) | -2(-4) | -2(-5) | -2(-6) |
|---|---|---|---|---|---|---|---|---|
| Return (1k) ↑ | 0.614 | 0.675 | 0.732 | 0.588 | 0.680 | 0.597 | 0.547 | 0.269 |
A3.2Guidance BufferControls εₖ · Theorem 4.5 (Q3) ↑
A moderate guidance buffer reduces CFM projection error by reusing recent improved action labels without letting targets become stale.
| Buffer Size | 0 | 10.24k | 51.2k | 102.4k | 204.8k |
|---|---|---|---|---|---|
| Return (1k) ↑ | 0.601 | 0.680 | 0.670 | 0.618 | 0.589 |
BibTeX citation
Displaying the BibTeX entry for your paper in a code block makes it easy to copy and paste.
@article{kim2026flag, title={FLAG: Flow Policy MaxEnt-RL by Latent Augmented Guidance}, author={Kim, Sungha and Lee, Gawon and Lee, Jusuk and Park, Jonghae and Kim, H Jin and Cho, Daesol}, journal={arXiv preprint arXiv:2605.30749}, year={2026}}